Retrospective on Loom®
August 13, 1999
Figure 1. Loom System Architecture
2.5 Contexts
4. Conclusions
4. References
In 1986, the University of Southern California’s Information Sciences Institute (ISI) began developing the Loom® knowledge representation system under DARPA sponsorship. Loom [Loom Guide 91, Brill 93, Loom Tutorial 95] was designed to support the construction and maintenance of "model-based" applications—Loom's model specification language facilitates the specification of explicit, detailed domain models, while Loom's behavior specification language provides multiple programming paradigms that can be employed to query and manipulate these models. Loom provides powerful built-in capabilities for reasoning with domain models, and it provides a variety of services for editing, validating, and explaining the structure of Loom models. Loom has seen active use within the DARPA and academic communities during most of its lifetime, and its development has been guided by needs originating with those communities. At the end of the Next Generation Knowledge Representation contract, which expired in March 1995, the Loom system was essentially complete. This report summarizes the results of work performed on that contract.
A typical Loom application program consists of an explicit, detailed model of the application domain, together with a procedural specification that defines the behavior of the application program. The Loom modeling language contains a rich set of primitives for constructing declarative representations of a model. This makes it possible for a relatively high percentage of a Loom application to be expressed declaratively, making the application easier to extend, modify, and debug. A crucial factor in the success of the Loom system is its ability to reason effectively with its declarative knowledge representation structures; as a consequence, declarative domain knowledge plays a more significant role in Loom applications than in those built using previous-generation technology.
Loom's reasoning architecture centers around an inference engine called a "classifier". ISI has been at the forefront in developing classifier technology during the last decade. The classifier has proved to be a means for (1) increasing the system's deductive power; (2) enabling significant improvements in system performance; and (3) coordinating the use of multiple special-purpose reasoners within a single software architecture.
Loom has been a continuously evolving system---each release of Loom supports additional reasoning capabilities, and for the past several years a new version of Loom has been released approximately once every nine to twelve months. One of our objectives has been to transfer new technology into the hands of users relatively early, so that feedback from users can be used to insure that each new feature of Loom satisfies real needs. Loom has been distributed to 100’s universities and corporations, and it was the common knowledge representation system for the ARPA/RL Planning Initiative. Technology transition has been accelerated by cooperative efforts between ISI and multiple DARPA contractors, including: Lockheed (software design libraries), UNISYS (developing an interface between Loom and a backend DBMS), ISX (implementing KRSL using Loom), USC (building a vision application using Loom), Stanford (interfacing Ontolingua to Loom), and University of Texas at Arlington (medical workstations). Within ISI, Loom has and is being used for applications such as natural language processing, intelligent user interfaces, automated logistics monitoring and prediction, explainable expert systems, diagnostic expert systems, and interfacing to multiple expert systems.
The Loom product represents a significant advance in knowledge representation technology. Making Loom a focal point for AI research has greatly increased cross-fertilization of ideas and technology, and lead to increased sharing and re-use of research results.
ISI began research in knowledge representation (KR) technology in the early 1980's. Joint work with BBN lead to the construction of the first KL-ONE-style classifier. Subsequent work produced a much faster classifier, called NIKL, that served as the KR system for a number of ARPA-sponsored projects at ISI. In 1986, ISI began work on an ARPA contract to design and implement a successor to the NIKL system. The resulting effort produced the Loom system, which has been under continuous development since that time. Projects at ISI began using Loom in 1988.
The job of the Loom classifier is to compute subsumption (superset/subset) relationships between concepts (unary relations) and to compute instance-of relationships between concepts and instances. Here is a simple example. Suppose a knowledge base includes the following Loom definitions and assertions
(defconcept Person)
(defrelation has-child :domain Person :range Person)
(defconcept Male)
(defconcept Person-with-Sons
:is (:and Person (:at-least 1 has-child Male)))
(defconcept Person-with-Two-Sons
:is (and Person (:exactly 2 has-child Male)))
(tell (Person Fred))
(tell (has-child Fred Sandy))
(tell (Male Sandy))
The classifier will determine that Person-with-Two-Sons is a subconcept of Person-with-Sons. It will also determine that Fred is an instance of the concept Person-with-Sons. Loom is unusual among classifiers in that it maintains the currency of its computations in the presence of modifications both to concepts (concept redefinition) and to instances (instance update). So, for example, if we retract the assertion that Sandy is Male, then the classifier will retract the inference that Fred satisfies Person-with-Sons.
Loom is the only classifier-based KR system designed to support the development of a broad spectrum of intelligent applications. Achieving this objective requires that Loom implement multiple styles of reasoning. Loom solves the problem of integrating multiple inference tools by providing multiple programming paradigms (data-driven programming, object-oriented programming, and logic programming) that are designed to work smoothly with each other and with the declarative knowledge base. Two factors contribute to Loom’s high level of integration: First, the Loom architecture is uniformly object-based. Second, wherever possible, the reasoners make use of the Loom classifier to provide needed inferences.
The first generation of commercially available knowledge representation systems (expert system shells) suffered from a number of deficiencies. First, these systems failed to make effective use of the problem solving and domain knowledge specified in applications programs. As a consequence, it was often difficult to understand and/or control the behavior of applications built with these systems. Because declarative domain knowledge played a less significant role than it should in applications built using those commercial tools, the knowledge in such application programs generally could not be shared or reused. Second, the various inference tools provided by those systems (the tools that comprise a "toolkit") were poorly integrated, making it difficult for more than one of the tools to be employed within a single application program. Third, the performance of the commercial shells was sufficiently poor that applications developed using them were frequently reimplemented using a traditional programming language (e.g., C) before being deployed in the field.
The second generation of commercial KR tools solved the problems of the first by scaling back the deductive power of their systems—they achieved better performance and integration by offering less functionality. Thus, while the early Loom system was often evaluated by comparing its capabilities to that of concurrent commercial systems, the gap between Loom’s capabilities and that of the next generation of commercial systems has widened, with Loom offering many more capabilities than commercial products.
Until the advent of ATT’s CLASSIC system [Borgida et al 89], none of the available commercial knowledge representation systems included a concept classifier. Like Loom, CLASSIC features a classifier-based architecture. However, CLASSIC is a more modest system than Loom. For example, CLASSIC's concept definition language omits many constructs identified as essential by NIKL and Loom users, CLASSIC does not provide a general-purpose query language, it does not support incremental updating of definitions (necessary in large applications), it has no production rule subsystem, and no context mechanism.
Another commercially available classifier-based system is the K-REP system developed at IBM [Mays et al 91]. K-REP features the ability to classify relatively large numbers of concepts. However, like CLASSIC, it has a relatively restricted concept definition language, and it does not provide the suite of complementary deductive capabilities that Loom provides.
The number of on-going efforts to develop comprehensive knowledge representation systems is quite small. The Cyc project begun at MCC is the largest of these. Cyc [Lenat & Guha 90] emphasizes the availability of a large base of "common sense knowledge", and provides sophisticated support for assisting humans in the task of knowledge acquisition. The focus within the Cyc project has been on the engineering of large common sense knowledge bases, and not on the advancement of deductive reasoning technology.
EPILOG [Schaeffer et al 93], and SNEPS [Shapiro et al, 95] are KR systems designed to support research in natural language understanding. These systems are designed primarily to support experiments in natural language understanding. They both feature relatively broad inferential coverage, and they place only a modest stress on performance.
At the close of the Loom contract in 1995, the leading KR systems that included concept classifiers were Loom, CLASSIC, K-REP, BACK, and KRIS. BACK [Peltason 91], developed at the Berlin Technical Institute, featured a moderately expressive concept definition language, and, like Loom, implemented a query processing capability in addition to the classifier. KRIS featured a complete reasoning facility for a concept definition language that was more expressive than the CLASSIC and K-REP languages, but less expressive than the Loom and BACK languages. Pier-Hein Speels’s doctoral thesis [Speel 95] contains a detailed comparison and evaluation of the Loom, CLASSIC, BACK, and KRIS systems applied to a specific application.
This section summarizes the architecture of the Loom knowledge representation system, and discusses the conceptual basis that motivates various design decisions. Loom is a large and complex system. Loom supports two distinct languages for making assertions and asking queries, and it implements several distinct forms of deductive inference. Below we describe each of these features, and discuss how they interrelate. We begin by outlining major architectural and conceptual components.
Loom recognizes two logical languages, a "description logic" language and a predicate calculus-based language. Loom’s description logic language resembles the KRSS language developed by participants in DARPA’s knowledge sharing effort [KRSS]. Loom’s predicate calculus resembles the KIF language developed by another working group within that same effort [KIF]. We will use the term "DL" to refer to the Loom description logic, and the term "PC" to refer to the Loom predicate calculus language. PC is strictly more expressive than DL—Loom users use the PC dialect whenever they wish to make a statement or query that cannot be expressed in DL. However, the Loom classifier can reason more powerfully with DL expressions than with PC expressions, and hence Loom users are encouraged to use the DL dialect whenever possible.
The principal deductive components in Loom are (1) a backward-chaining query facility; (2) a description classifier; and (3) a production-rule system. Orthogonal to these components are (4) a context mechanism; (5) default reasoning; and (6) temporal reasoning. Knowledge entered into a Loom knowledge base is categorized as being a definition, a (material) implication, a default implication, a production rule, or a factual assertion. Each reasoner uses whichever of these forms of knowledge is appropriate (e.g., all reasoners use definitions, while production rules are used only by the production system).
Figure 1 illustrates the overall Loom architecture.
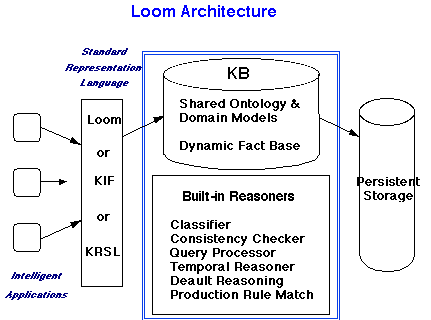
Figure 1.
Developers outside of the Loom project have constructed translators that enable users to use more than one language for interfacing to Loom. Thus, besides the DL and PC languages, users can also communicate using either KIF or KRSL. The core Loom system consists of a suite of tightly integrated reasoners that manipulate a shared knowledge base. The LIM system [Pastor and McKay 91] developed by UNISYS/Paramax/Loral enables Loom to be connected to an ORACLE DBMS. The capabilities of the Loom-to-ORACLE bridge have been enhanced by the PERK system [Karp, Paley, Greenberg 94] developed at SRI—PERK enables Loom’s communication to the DBMS to be transparent to a Loom application.
Loom satisfies certain design requirements that we believe are essential in an efficient, general-purpose knowledge representation system. These criteria have a strong impact on the kinds of inference strategies that we have implemented within Loom and they force choices that are different than those found in many other AI tools. In this section we list these design requirements, and then discuss their motivation, and how they impact the system architecture (see [Doyle & Patil 91] for an alternate discussion of requirements for a KR system).
Our requirements for a general-purpose knowledge representation system are:
Loom’s description logic is too expressive to allow for complete reasoning (it is provably undecidable). Therefore, each form of deductive inference implemented for Loom is necessarily incomplete. As system designers, we therefore face the problem of deciding how complete the reasoning should be. We have made different choices for different components—backward chaining and production rule firing generally favor performance (speed) over depth of inference, while the classifier favors depth of inference over performance. Hence, the classifier’s reasoning is more complete than that used by each of the first two reasoners.
Many previous-generation systems require that users mark rules as "forward" or "backward" to indicate how they should be used by an inference engine. We believe that this practice runs contrary to the philosophy of a declarative knowledge based system. Also, this practice doesn’t make sense when the rules can be used by different reasoners, as is the case for Loom, since some reasoners may favor backward chaining while others may favor forward chaining. In Loom, the choice of running rules using forward chaining versus backward-chaining is hardwired into the system (users cannot control it). The description classifier uses forward chaining to reason with all forms of implications. The query system uses backward chaining to reason with implications. The query system recognizes only those implications for which backward chaining can be executed with reasonable efficiency; other implications are ignored (in general, rules with simple consequents are backward-chained, while rules with complex consequents are not).
Loom has developed a new, object-oriented approach that enables users to trade between performance and inferential depth in their applications. Instances in a Loom knowledge base can be a mixture of ordinary CLOS objects and (much more complex) objects implemented using Loom-specific data structures. The Loom query facility and production rule system can reason with both kinds of instances. The Loom description classifier can reason only with the latter (more complex) objects. Applications that don’t require the depth of inference enabled by the classifier can save both space and time by using only the simple form of instances. Loom enables users to switch between classified and unclassified instances, so they are free to experiment if they are unsure whether or not their application benefits from use of the classifier.
The Loom query processor evaluates expressions phrased in the Loom PC language, and returns lists of instances or tuples that satisfy such an expression. The functionality of the query processor is roughly equivalent to that of a deductive database processor. A key design criterion is that the processor must be fast—it is intended for processing queries embedded in a user application, for evaluating the antecedent portions of Loom production rules, and it is used to implement portions of the description classifier. Therefore, the performance of Loom and of Loom applications depends directly on the efficiency of the query processor.
Loom achieves high efficiency by (1) optimizing each query before it is executed, and (2) converting each query into Common Lisp code and then compiling that code. Compiled query code is generated for each Loom concept definition and relation definition as well as for individual query commands. Intermediate query states (control flow and variable bindings) are managed using the control stack built into Common Lisp (this contrasts with a Prolog-style processor where control flow and variable bindings are managed explicitly on stacks manipulated by the Prolog engine). The resulting queries are very efficient—in most cases, Loom queries are as efficient as hand-coded queries.
Database query languages (like SQL) and Horn logics (like Prolog) are carefully designed (restricted) so that query evaluation can be both efficient and complete. Unfortunately, these languages are too restrictive to be used in a general-purpose knowledge representation system. Loom users want the convenience of the full first-order predicate calculus, augmented with definitions and implication rules. Therefore, we cannot expect that the Loom query processor will deliver complete inferences. This raises the question of how incomplete the Loom reasoner actually is. Most AI researchers have shied away from constructing incomplete deductive reasoning systems, i.e., the problem of how to design a deliberately incomplete reasoner has received very little attention. We consider this an important contribution of the Loom architecture. Below and in the next section we discuss some of our design decisions with regard to inferential completeness. We will first present an example that brings the issue of incompleteness into sharper focus, and then we briefly discuss our approach to crafting an incomplete query processor.
Suppose we have the following Loom definitions:
(defconcept A)
(defconcept B)
(defrelation R)
(defconcept AwR :is (and A (at-least 1 R)))
(defconcept BwR :is (and B (at-least 1 R)))
(defconcept AB :is (and A B))
(defconcept C :is-primitive BwR)
(implies AB C)
Now suppose we assert that instance Fred belongs to each of the concepts A and B, and that instance Joe belongs to the concepts A and BwR:
(tell (A Fred) (B Fred))
(tell (A Joe) (BwR Joe))
The above definitions together with the one implication imply that Fred and Joe are instances of all of the concepts named above. However, if we use the Loom query processor to evaluate the instantiation relationship between each concept and Fred, and between each concept and Joe, the query processor will yield a complete result (the value true) for all questions except that it will fail to determine that Fred is an instance of the concept AwR. For example, it will yield the following answers:
(ask (AB Joe)) -> true
(ask (AwR Joe)) -> true
(ask (AB Fred)) -> true
(ask (AwR Fred)) -> unknown
To predict which inferences the query processor will find and which it won’t, it is necessary to understand the proof strategies that it uses. The top-level strategies used by the Loom backchainer are relatively straightforward: To determine if an instance X belongs to a concept D, the query processor tries three proof techniques (1) it checks to see if X is asserted to belong to D or to one of its subconcepts; (2) if D has a (non-primitive) definition, it evaluates whether the components of the definition are satisfied by X; (3) if D is the consequent of one or more implication rules, then it tests to see if X satisfies the antecedent condition of some one of the rules.
Now we can apply these strategies to the above example. Membership in the concept AB is determined by referencing its definition—since Fred is asserted to be an instance of both A and B, the query processor infers that Fred belongs to AB (the same reasoning applies to Joe). In the case of a concept like AwR, the query processor tests a trial instance for membership in A, and it evaluates whether or not the restriction (at-least 1 R) is satisfied by the instance. Because Joe is asserted to belong to BwR, Joe has inherited the restriction (at-least 1 R), and hence both tests succeed. However, Fred does not inherit this restriction; when asked whether Fred satisfies AwR, the backchaining strategy described above (techniques 1-3) cannot find a sequence of rules that proves that Fred satisfies the restriction (at-least 1 R), and hence the query processor fails in this case.
It is unsettling to recognize that the query processor is incomplete. But the fact of the matter is if we want our query processor to be fast, then we have to draw the line somewhere, i.e., we have to limit its inferencing capabilities. The key question is, "Where should the line be drawn?" We believe that the choice of where to draw the line should be guided principally by performance considerations, and secondarily by a simplicity argument—determining whether or not an inference engine can or cannot derive a particular inference should be as simple as possible within the bounds of practicality.
It should be noted that if Loom’s classifier is enabled, then it will discover the fact the Fred satisfies AwR (it will classify Fred as an instance of AwR). Since all inferences made by the classifier are visible to the query processor, in this case the query processor will derive correct (complete) answers to all questions relating to the above set of definitions and facts. In general, the combination of query processor and classifier is more powerful than either by itself; the classifier is more complete over the domain of definitions and axioms that it recognizes, while the query processor can reason with PC expressions that are effectively opaque to the classifier.
The inference strategy for the Loom query engine outlined above is relatively simple. However, our discussion glossed over the issue of how logical connectives within a defined query are evaluated. A conjunctive expression within a query evaluates to true if all individual conjuncts are satisfied. For the case of disjunctions, the query engine returns true if (at least) one of the disjuncts is satisfied, but (like Prolog) the Loom query processor does not perform non-unit resolution of disjuncts. Unfortunately, we have not identified a clear-cut strategy for evaluating negated expressions. Loom implements a variety of strategies for finding disproofs, and we don’t yet have a compelling argument for determining which strategies deserve to be implemented. This is an area that deserves further study.
The key finding for our implementation is that users have been satisfied with the query semantics as currently implemented. We occasionally receive reports of incomplete reasoning associated with Loom’s description classifier, but have never received a complaint regarding the incompleteness of the backchainer. Our experience with Loom indicates that users have a relatively conservative set of expectations regarding what inferences a backward-chainer should be expected to infer, and that the Loom query processor succeeds in matching those expectations.
A key design objective for the Loom production rule system (PRS) was that it should integrate smoothly with other Loom inference components. For example, it correctly finds matches for production rule variables bound to defined concepts (concepts that have self-contained logical characterizations), and it exploits any matches found by the Loom instance classifier. Production rules are sensitive to context. The context semantics is carefully designed to distinguish between assertions made by a user (which inherit down to child contexts) and assertions performed by the PRS (which don’t inherit to child contexts). Thus, within a context hierarchy, the same production rule may trigger differently at different levels.
As with every other Loom reasoner, one must decide which inferences (matches) the PRS should and should not find. While implementing the PRS, we found it tempting to take advantage of some of the inferences represented within caches maintained by the PRS. For example, using the same definitions, implication, and assertions as in section 2.2 above, suppose we have also defined production rules that will fire whenever an instance is determined to satisfy either AwR or BwR. To assist the match process, the PRS establishes caches that indicate which instances currently satisfy each of these concepts. Using backward chaining, the PRS will determine that Fred and Joe both satisfy the concept BwR, and thus it will place both of them into the cache for BwR. The caching of concept membership relations conceptually represents a forward-chaining operation. We were initially tempted to exploit this (forward-chained) inference to infer additionally that Fred satisfies the restriction (at-least 1 R), leading to the inference that Fred satisfies AwR.
Taking advantage of cached inferences in this way would not be a good idea—for this example, the PRS would find the match between Fred and AwR only for the situation when some production rule exists that monitors BwR; in other situations, the match between Fred and AwR would not be found. Hence, the matcher’s behavior would appear unpredictable. After some experimentation, we decided that the best (and simplest) choice would be for the production rule match to find matches only for those cases when the backward-chainer could make the same inferences. Loom users appear to be satisfied with this design choice—as is the case with the query processor, we have received no complaints from Loom users regarding the completeness of the production rule matcher.
For additional discussions on the Loom production rule facility see [Yen et al 89, Yen et al 91b].
The Loom description classifier complements the backward-chaining query processor by providing a forward chaining inference capability. At the concept and relation level, the classifier can infer the existence of subsumption relations between defined concepts—the query processor exploits these relations to increase its inferential power. At the instance or fact level, new factual relations derived and cached by the classifier are also used by the query processor to increase its inferential capabilities.
The Loom classifier is capable of classifying only a subset of all first-order-definable concept definitions, namely, those phrased in the DL language. Loom’s DL is more expressive than that found in any other existing description-logic-based knowledge representation. However, many Loom users want still more expressive power. Rather than continually extending the expressive power of the Loom DL language, we consider it preferable to abandon DL altogether. We have constructed a prototype classifier for definitions phrased using the PC language [MacGregor 94]. This PC classifier is used within the PowerLoom® system [PowerLoom] being developed under a subsequent DARPA contract.
The Loom classifier is one of only two existing classifiers that permits revision of concept and relation definitions (the other is the BACK classifier developed in Berlin). This makes it uniquely well suited for managing large knowledge bases. Loom also supports revision of facts attached to classified instances. The expressiveness of the Loom DL makes instance revision more difficult to implement than would be the case for a more limited DL.
The Loom classifier has consistently performed well on performance benchmarks [Profitlich et al 92]. This despite the fact that all such tests focus on the speed of concept classification, while Loom is tuned primarily to accelerate the speed of instance classification. While the Loom classifier performance has proved to be adequate for moderately large knowledge bases, we have observed that new indexing techniques will need to be developed to efficiently classify concept bases that contain a large percentage of non-primitive concepts.
Due to the expressiveness of its DL language, the Loom classifier is necessarily an incomplete reasoner. Our goal was to make the classifier sufficiently complete so as to find all inferences expected by members of our user community. Unfortunately, in response to user requests for more expressive power, the Loom DL has been continuously extended, with the result that new sources of incompleteness have sprung up as fast as we have patched up old ones. Thus, our goal has not yet been achieved. We have, however, demonstrated that an incomplete classifier is useful for a variety of applications.
As far as we know, Loom is the only system that attempts to define a unified context mechanism to handle both long-lived contexts (Loom calls these "theories") and short-lived contexts (often called "worlds"). We have developed a semantics for contexts that applies to both theories and worlds. In some cases, we found ourselves forced to choose between theoretical elegance and practicality—in these cases, practicality won out.
For the case of single inheritance, the Loom semantics is straightforward—all assertions in a parent context inherit to a child context, recursively. An inherited assertion can be subsequently retracted by a child context, i.e., inherited assertions and local assertions are treated the same by the retraction mechanism.
Multiple inheritance is a bit more complicated. A newly created child context inherits all assertions from its left-most parent, and then from each successive (going from left-to-right) parent, it inherits all assertions not already present in the child. This means that multiple inheritance favors the right-most parents, since a later-inherited assertion may override an assertion inherited earlier (this is called "clipping" in Loom terminology). The asymmetry of the semantics represents a compromise for the sake of efficiency. We were able to identify a conceptually cleaner semantics that doesn't treat inherited assertions asymmetrically, but the computational overhead to implement it was prohibitive. Note that if clipping is disabled, then symmetry is restored—in general, the semantics is symmetric for the case that all updates are monotonic.
The semantics for the case of updates to internal (non-leaf) contexts poses a problem. We take for granted that each externally generated update to an internal context should be applied recursively to all of its child contexts. However, we decided that updates that derive from production rules should not be inherited. The driving factor in this decision was the possibility that an update to an internal context would trigger production rules that would generate further updates to the same context. While it makes sense that the original assertion or retraction should inherit down to the children, it in general does not make sense that side-effects generated by that update should also inherit down, since the "context" of the rule firing is different for the parent than the child, and may not make sense for the child.
Loom definitions and non-factual axioms are not context-sensitive—an inherited definition/axiom cannot be retracted in a child context. Some Loom users have requested such a capability, but we did not have the resources to implement it.
The prevailing view among AI theoreticians regarding the semantics of default rules is that (1) conflicts should be resolved within the logic, and that (2) deterministic semantics should be obtained using complex, computationally expensive evaluation procedures. We believe that such an approach to default rules semantics is fundamentally wrong. Our viewpoint is buttressed by the fact that the impact of these kinds of default systems for real applications has been essentially nil.
The semantics adopted for the Loom system assumes that (1) conflicts generated by default inferences should be resolved by extra-logical means, and that (2) a strategy to insure deterministic behavior of default rules should be as simple and efficient as possible. Loom implements a restricted form of default rule—the antecedent clause of a Loom default rule corresponds to a monadic predicate. Also, default rules are "normal"—the consistency check involves testing that the consequent does not yield an immediate conflict. This means that each default rule can be associated with a Loom concept. Preference semantics among default rules is based upon the subsumption relationships of among the corresponding concepts.
Philosophically, we regard the relationship of default rules to strict first order logic as being analogous to the relationship of methods to a standard programming language—the defaults exist to "soften" up the logic and make it more flexible, so that the system can more easily adapt to a variety of situations. In an object-oriented program, if a situation arises when the behavior of an applicable method is inappropriate, this is considered a "bug" in the program. We take the same viewpoint with default rules: if a situation arises when the applicable default rule yields an undesired inference, then the knowledge base is buggy. The fix is usually to introduce a new default rule of higher precedence (greater specificity) whose consequent yields the desired inference.
To obtain a deterministic semantics, Loom evaluates all default rules in parallel: Rules are fired in cycles. During each cycle, all rules whose antecedents are satisfied and whose consequents don’t yield a conflict are identified. The consequences of each rule are then applied in parallel to the knowledge base. The next cycle will identify a new set of default rules, which are again applied in parallel. The cycles continue until a conflict occurs, or until no additional default rules can be applied. The consistency check that predicts whether or not the application of a default rule will lead to conflict is unusual—instead of testing for consistency against all asserted and derived facts, the rule’s consequent is tested only against monotonically derived facts. This test is therefore weaker than the check for inconsistency that occurs after a default rule is applied. Basing the consistency test only on monotonic knowledge guarantees that when the result of applying a sequence of default inferences yields a consistent knowledge base, the resulting set of derived facts is necessarily independent of the order in which the default rules were applied. Thus, unlike, for example, skeptical reasoners that apply very expensive consistency checks, Loom applies a relatively efficient test. Conflicts resulting from default inferencing are treated the same as they are for strict inferencing—the offending instance is marked as incoherent, and it is left to the application to generate an update that removes the conflict.
In addition to default rules, Loom also supports the closed world assumption, i.e., it supports two distinct forms of non-monotonicity. Originally, Loom was designed so that strict inferencing was performed using the open-world assumption, while the closed world assumption was applied (for rules referencing those relations declared to be closed) only during the default rule cycles. We later decided that closed world semantics deserves a higher preference than default rules. Hence, Loom was redesigned so that after the strict open world inferencing, there is a new phase in which strict rules are reevaluated under the closed world assumption. This new phase precedes the application of default rules, resulting in a finer-grained stratification of the non-monotonic inferences.
The Loom default rule semantics results in an implementation that is computationally tractable—the computational overhead in real applications is comparable to that of Loom’s monotonic inferencing. In practice, Loom applications appear to use defaults very conservatively, so that conflicts do not arise. Hence, we consider the Loom default semantics to be an indicator that practical default inferencing systems can indeed exist.
In this section we discuss some lessons learned from the construction and day-to-day use of the Loom system, and we outline what choices will be different in the next classifier-based KR system that we are constructing.
The Loom classifier uses a proof technique called "structural subsumption" to test for subsumption relationships. The proofs found by such a classifier are shallow when compared to the proofs derived by a resolution-based classifier (discussed below). However, the level of completeness available using structural subsumption has proven to be satisfactory to almost all Loom users. One major drawback of the Loom classifier is that its inference strategies are hardwired into the system. A better architecture would enable users to write their own (second order) rules of inference, to be used by the classifier to augment a definition. Users who wanted inferences missed by the classifier would then have the option of introducing their own rules, and thereby making the classifier more complete with respect to their own needs.
The primary alternative to the structural subsumption approach to classification is one based on (tableau-based) resolution. The resolution-based approach is capable of uncovering subsumption relationships that cannot be proved using a structural approach. However, it has several drawbacks: While its performance over terminological (Tbox) knowledge is good, it exhibits poor performance on axiomatic (Abox) knowledge. We expect that for moderately large knowledge bases (having, say, 100 to 1000 instances), the resolution approach will prove impractical. We aim in the future to support knowledge bases with up to a million instances. A second drawback to resolution is that the nice completeness properties it exhibits on some description logics evaporate when one moves to more expressive logics; for expressive logics, a resolution approach cannot guarantee either completeness or termination (unless a depth cut-off is applied). Finally, resolution approaches fail in the presence of inconsistent knowledge. We believe that for very large knowledge bases, inconsistency will be common place, and inference engines that reason with them will be required to function coherently in the presence of inconsistency. Structural subsumption has the nice property that it doesn’t go off the deep end in the presence of inconsistent knowledge.
One of the nice features of Loom is that it truth-maintains all inferences derived by the classifier. For logics more expressive than a description logic, it is not clear that a reasonably efficient strategy for truth maintenance of assertional (ABox) knowledge exists. Our next system will be experimenting with alternatives to truth maintenance. We have in mind an approach we call "just-in-time" inference that would defer classifying instances until they are accessed by an application, and that would discard cached inferences rather than trying to truth-maintain them in the presence of updates.
Here we comment on some mistakes we made in the Loom architecture, and suggest what we should have done.
The simplest way to implement an instance classifier is to create a concept representing each instance to be classified, to classify that concept using the concept-classification machinery, and then to propagate the subsumption links to the instance. Early in the Loom design, we conjectured that this is a bad strategy, and we didn’t implement it. However, Loom does introduce new "conjunction concepts" whenever it classifies an instance as belonging to more than one concept. In retrospect, this partial adoption of the above-mentioned strategy was a big mistake—the concept network becomes "polluted" with system-defined concepts that reduce the performance of the system. Our new classifier will avoid generating any system-defined concepts as a by-product of subsumption tests.
In Loom, concepts are first class objects, but arbitrary (unnamed) descriptions are not. This is a mistake—descriptions should be first class objects as well. From NIKL, we borrowed the idea of allowing concepts to point directly at each other internally, and we implement concept merging by relinking all pointers to an about-to-be-merged concept to the about-to-be-merged-into concept. Both of these decisions were unfortunate—the bookkeeping required to maintain consistency in the presence of concept revision is enormous, and the programmer effort required to make this work correctly is very high. Our new classifier introduces objects called "surrogates" that serve as stand-ins for concepts. Most concept references point to a surrogate rather than directly at a concept object. When a concept is revised, a new concept object is created to accommodate the new definition, and only the surrogate pointer need be transferred from the old version of the concept to the new one.
All classifiers that we know of take an all-or-nothing approach to concept and instance classification—they do not support the ability to classify only a few concepts or instances at a time in a knowledge base. For large knowledge bases, this approach causes the process of loading a large knowledge base to take much too long. For our new classifier, we will be experimenting with "just-in-time" and background classification schemes that will enable very fast loading, as well as partial loading of a knowledge base.
Certain spokespersons within the description logic (DL) community consider their systems to be inherently "object-oriented" (O-O). While it is true that their systems are "concept oriented", typical DL system architectures clash with object-oriented notions in several different ways:
Our experience with Loom indicates that most users prefer to define functions rather than relations, that the O-O notion of a role/slot should be a fundamental building block within a class/concept, and that polymorphic functions and relations are the norm rather than the exception, and that Boolean-valued functions are a good thing. In particular, single-argument Boolean-valued functions provide an elegant means for introducing the notion of "property" that is absent in DL systems. Hence, we conclude that existing DL systems are definitely not object-oriented (but they should be).
Theoreticians have identified three distinct semantics (greatest fixed point, least fixed point, and descriptive) to describe possible semantics for recursive (self-referential) concept definitions. Loom does not support recursive definitions, but its successor will. Greatest fixed-point semantics appears to be the correct choice—of the three, it seems most harmonious with a structural subsumption proof strategy.
DL systems (including Loom) typically require that disjointness relationships between concepts be specified explicitly using some form of "disjoint-partition" operator that enumerates a set of mutually disjoint concepts. This is tedious and awkward. Many O-O systems assume that all classes/concepts that do not share a common subclass are disjoint be default. Cyc [Lenat & Guha 90] contains some innovative (and convenient) means for specifying that concepts below a common superclass are mutually disjoint. In our next KR system, we intend to adopt one (or perhaps both) of the latter strategies for specifying disjointness.
We have stated in many places that a description logic, even a very expressive one like Loom’s, is not expressive enough to form the sole basis for a knowledge representation system. A simple expression like "parents who have more sons than daughters" cannot be expressed in any of today’s DLs. Description logics also cannot express modal operators, e.g., "John believes that he is crazy" or "The probability that we are in Belgium is 0.1429". We believe that the ability to represent the equivalent of the full first-order predicate calculus is a minimal requirement for a general-purpose KR system.
This leaves open the question of what logic/language the system should support. Our experience suggests that no single language will satisfy the majority of potential users. Instead, a KR system should be able to interpret multiple languages (even though it internally will favor one), and it should be able to present answers in more than one language. The ability to input and output KIF is a good start for a KR system, since KIF is the only AI logic undergoing formal standardization. We have observed, however, that many users find KIF syntax (and that of the predicate calculus in general) to be non-intuitive.
Other candidates for input languages include a vanilla frame language, Object SQL, and the KRSS description logic. It is technically rather easy to write translators from a less expressive language into a more expressive language, so recognizing multiple languages should not be a problem. Output from a complex representation into a simpler one is much more difficult. Translators exist that can translate that subset of a knowledge base that is "frame-oriented" into a variety of other languages. This will probably suffice for the bulk of answers output by a KR system, at least in the near term. If and when users come to expect complex answers from a KR system, then the translator problem will be significantly harder to solve.
Loom implements a suite of KR functions whose use has been validated by the substantial Loom user community. Although newer KR systems have come into being since Loom’s release, as far as we know, Loom still has the largest user base of any KR system. We attribute this to the comprehensiveness of Loom’s services; other KR systems offer only a subset of the services that Loom provides.
Although Loom’s roots are in the description logic community, whose members place a stress on complete reasoning, Loom demonstrates that there are plenty of users willing to sacrifice deductive completeness for the sake of greater expressive power. Loom also validates the use of hybrid representation languages, as it supports both a description logic language and a predicate calculus language.
Finally, Loom demonstrates that multiple programming paradigms can be successfully integrated within a single KR tool. Multi-paradigm tools were one of the "Holy Grails" of KR systems during Loom’s early years, but Loom’s competitors in this game dropped out without having achieved success.
[Baader & Hollunder 91] Franz Baader and Bernhard Hollunder, "KRIS: Knowledge Representation and Inference System," SIGART Bulletin 2,8-14, special issue on implemented knowledge representation and reasoning systems.
[Borgida et al 89] Alex Borgida, Ron Brachman, Deborah McGuinness, and Lori Halpern-Resnick, "CLASSIC: A Structural Data Model for Objects", Proc. of the 1989 ACM SIGMOD Int’l Conf. on Data, 1989, pp.59-67.
[Brill 93] Dave Brill, Loom Reference Manual, for Loom Version 2.0, http://www.isi.edu/isd/LOOM/documentation/manual/quickguide.html, December 1993.
[Doyle&Patil 91] Jon Doyle and Ramesh Patil, "Two Theses of Knowledge Representation: Language Restrictions, Taxonomic Classification, and the Utility of Representation Services", Artificial Intelligence, 48, 1991, pp.261-297.
[Karp, Paley, Greenberg 94] Peter D. Karp, Suzanne M. Paley, Ira Greenberg: "A Storage System for Scalable Knowledge Representation", in Proceedings of the Third International Conference on Information and Knowledge Management (CIKM'94), Gaithersburg, Maryland, November 29 - December 2, 1994, ACM Press. 97-104.
[Kasper 89] Robert Kasper. "Unification and Classification: An Experiment in Information-based parsing." Proceedings of the Intern’l Workshop on Parsing Technologies, Pittsburgh, PA, August 1989.
[KIF] Knowledge Interchange Format Specification, http://logic.stanford.edu/kif/specification.html.
[KRSS] http://www-db.research.bell-labs.com/user/pfps/papers/krss-spec.ps.
[Lenat & Guha 90] Douglas Lenat and Ramanathan V. Guha, Building large knowledge-based systems: representation and inference in the Cyc Project, Addison-Wesley Publishing Company, Inc., Reading, Massachusetts, 1990.
[Loom Tutorial 95] Tutorial for Loom version 2.1., http://www.isi.edu/isd/LOOM/documentation/tutorial2.1.html, May 1995.
[Loom Guide 91] Loom User's Guide for Loom version 1.4. ISX Corporation, http://www.isi.edu/isd/LOOM/documentation/usersguide1.4.ps, August 1991.
[MacGregor 88] Robert MacGregor, "A Deductive Pattern Matcher," in Proceedings of AAAI-88, The National Conference on Artificial Intelligence, 1988a.
[MacGregor 90] Robert MacGregor, "The Evolving Technology of Classification-based Knowledge Representation Systems", Principles of Semantic Networks: Explorations in the Representation of Knowledge, Chapter 13, John Sowa, Ed., Morgan-Kaufman, 1990.
[MacGregor 91] Robert MacGregor, "Using a Description Classifier to Enhance Deductive Inference", Proc. Seventh IEEE Conference on AI Applications, Miami, Florida, February 1991, pp 141-147.
[MacGregor&Burstein 91] Robert MacGregor and Mark H. Burstein, "Using a Description Classifier to Enhance Knowledge Representation", IEEE Expert, 6:3, June, 1991, pp.41-46.
[MacGregor&Brill 92] Robert MacGregor and Dave Brill, "Recognition Algorithms for the Loom Classifier", Proceedings Tenth National Conference on Artificial Intelligence, San Jose, CA, July 1992.
[MacGregor 93] Robert MacGregor. "Representing Reified Relations in Loom," in Journal of Experimental and Theoretical Artificial Intelligence, 5:179-183, 1993.
[MacGregor 94] Robert MacGregor, "A Description Classifier for the Predicate Calculus", in Proceedings of the Twelfth National Conference on Artificial Intelligence, (AAAI 94), pp. 213-220, 1994.
[Mays et al 91] Eric Mays, Robert Dionne, and Robert Weida, K-REP System Overview, SIGART Bulletin, 2(3), 1991, pp.93-97.
[Pastor and McKay 91] Jon Pastor and Donald McKay, "View-Concepts: Knowledge-Based Access to Databases", http://www.navpoint.com/~pastor/jon/Papers/View%20Concepts/VC-5-006.html.
[Peltason 91] "The BACK System - An Overview", SIGART Bulletin, 2(3), 1991, pp.114-119.
[PowerLoom] http://www.isi.edu/isd/LOOM/PowerLoom-work/.
[Profitlich et al 92] Jochen Heinsohn, Danial Kudenko, Bernhard Nebel, and Hans-Jürgen Profitlich, "An Empirical Analysis of Terminological Representation Systems", AAAI-92 Proc. of the Tenth Nat’l Conf., San Jose, Calif., 1992, pp. 767-773.
[Schaeffer et al 93] S. Schaeffer, C. H. Hwang, J. de Haan, and L. K. Schubert. "The User's Guide to EPILOG" (Prepared for the Boeing Co., Seattle), U. of Alberta, Canada, 1993.
[Shapiro et al, 95] S. C. Shapiro and The SNePS Implementation Group, "SNePS 2.3 User's Manual", Department of Computer Science, University at Buffalo, Buffalo, NY, 1995.
[Speel 95] Piet-Hein Speel, Selecting Knowledge Representation Systems, Thesis Universiteit Twente Enshede, 1995.
[Yen et al 89] John Yen, Robert Neches, and Robert MacGregor, "Using Terminological Models to Enhance the Rule-based Paradigm," in Proceedings of the Second International Symposium on Artificial Intelligence, Monterrey, Mexico, October 1989.
[Yen et al 91a] John Yen, Hsiao-Lei Juang, and Robert MacGregor, "Using Polymorphism to Improve Expert System Maintainability", IEEE Expert, 6:1, April, 1991, pp.48-55.
[Yen et al 91b] "CLASP: Integrating Term Subsumption Systems and Production Systems," John Yen, Robert Neches, and Robert MacGregor. In IEEE Transactions on Knowledge and Data Engineering, Vol. 3, No. 1, pp. 25-32, 1991.
![]()
![]()